Visualizing the Perfect AI Agent: The Geometry of AI Agents and The Curve of Regret
An attempt to make sense of what it means to delegate thought, sketch a geometric intuition for how capability and agency shape the surface of an agent’s value, and where that surface can quietly collapse.

The year is 2025. Everyone’s an AI agent architect. Everything is an agent. My code is an agent. My coffee machine is an agent. And, apparently, my neighbor's cat is too?
LinkedIn would have you believe that anything short of autonomous tool-using reasoning systems is yesterday’s news. But somewhere we lost something important: a grounded way to talk about what these systems actually do.
Before we begin, I want to share a simple goal: to make sense of what it really means to call something an agent. Not in abstract terms, but in a way that’s concrete, visual, and, hopefully, a little bit beautiful. I’ll try to sketch out a geometric intuition for how I think we might define an agent’s capability surface, what it is we’re actually optimizing, and how things can go subtly (or spectacularly) wrong when autonomy outpaces understanding.
As always, these are my personal thoughts — not the views of any team, organization, or institution I’m affiliated with.
What Are We Actually Optimizing For?
Intelligence isn't the goal. Autonomy isn't either. What we really want is to stop thinking about something — and trust that it will be handled.
Defining an Agent?
agency
noun
Pronunciation: /ˈā-jən(t)-sē/
Plural: agencies
Definition:
The capacity, condition, or state of acting or of exerting power: operation.
There’s been a lot of debate lately about what really counts as an agent. Some argue that even a basic chatbot qualifies. After all, if it can replace a human agent in a task, say, answering questions with no external tools, isn’t that enough?
Maybe. But I think it’s worth going back to first principles.
Let’s start with the word itself: agency. At its core, agency is the capacity to act — to exert power, to cause something to happen. And while we often treat it as a binary ("does it have agency or not?"), it’s more useful to think of it as a continuous spectrum. Some systems act more than others. Some act with more precision, more autonomy, or more scope.
For the purposes of this post, I’m going to define an agent as any LLM-powered system with some capacity to act on its environment, even if that capacity is small. The degree of agency might vary, but the defining feature is the presence of it.
What Makes a Good Agent?
Now that we’ve defined what an agent is, the next question is: what makes one good?
Is it the amount of agency it has? The size of its context window? Its ability to browse the web or call functions?
Not exactly.
Over the last few months, we’ve seen a wave of agent benchmarks — measuring everything from task success to plan quality to graceful failure. These are important. But I’d argue they’re all proxies for something deeper: cognitive delegation.
Because at the end of the day, that’s the real goal, not just of agents, but of AGI itself: to offload thinking. To hand a task, a problem, or a decision to a system and trust that it will be handled — not perfectly, but well enough that you don’t have to think about it anymore. That’s cognitive delegation. And it’s what makes a good agent good.
A basic LLM-powered chatbot already reduces cognitive load in subtle but meaningful ways. It lets us ask instead of search, and synthesize instead of sift, collapsing the multi-tab chaos of web search into a single coherent response. But agents promise to go further. Not just help me think, but handle it for me.
A Few Caveats
- Cognitive delegation doesn’t necessarily require AI.
A simple RPA script that enters data into a form is delegation, too — just rigid, narrow, and brittle. The less flexible the system, the more cognitive load it still pushes back onto the human. - Delegation can be negative.
Some systems don’t reduce cognitive load — they increase it. If it takes more time, more verification, or more overhead to use the system than to just do the task yourself, that’s negative cognitive delegation.
So for the rest of this post, I’m going to treat cognitive delegation as the true optimization objective, even if we can’t directly measure it. Benchmarks may test different proxies: success rates, error types, efficiency, and so on. And that’s fine; it’s hard to measure something that changes person to person. But proxies only work when we remember what they’re standing in for. And what they represent is our ability to think less and trust more.

Agency & Capability: The Principal Components of Delegation
There are many knobs you could tune. But most of them collapse into two: how smart the model is, and how much power it has.
Now that we’ve defined our north star, cognitive delegation, the natural question is: What are the variables we can actually control to move toward it?
In other words: if we’re doing gradient ascent toward better delegation, what are the axes of that space?
In practice, there are many. The structure we give the agent. The model we use. The context window. The prompt template. The API spec. The modality. And these knobs don’t just vary between systems – their importance shifts from task to task.
But the beauty of abstraction, and math, is that we can often collapse high-dimensional spaces into something more tractable. Anyone who’s taken a stats course knows where this is going: principal component analysis. The idea is simple: reduce the dimensionality of a system while preserving its signal.
So for the sake of visualization, I’m going to collapse these countless knobs into just two:
- Capability — how intelligent the system is
- Agency — how much control it has over the environment
These aren’t the only variables that matter. But in most systems I’ve worked on, they explain the majority of the variance.
Take context, for example. It matters – of course it does. But if a model is capable enough to traverse, interpret, and retain the right context and it has the agency to go fetch it on demand… hasn’t the problem resolved itself?
Or take structure: workflows, tool specs, wrappers. All useful. But often, they’re just scaffolding compensating for limited agency or insufficient capability.
Yes, this is an abstraction. Yes, it’s incomplete.
Why Capability × Agency ≠ Delegation
We now have our three axes – just enough to think visually.
- Capability sits on the X-axis. This is the model’s raw intelligence: its reasoning ability, general knowledge, and capacity to synthesize. Think of it as the difference between Claude Haiku and Claude Sonnet, or more generally, between an enthusiastic intern and someone who actually knows what they’re doing.
- Agency lives on the Y-axis. This is what the system is allowed to do — what tools it can call, what systems it can affect, how much real-world power it has. A chatbot that just replies to your prompts? Low agency. A system that can spin up cloud instances, traverse your internal tech stack, and auto-deploy itself to production? High agency. (Sign here to void your incident response SLAs)
- Finally, the Z-axis is cognitive delegation — how much mental effort we can offload to the system. This is the metric we care about most.
And while delegation obviously depends on both capability and agency, the relationship isn’t as tidy as:
Delegation = Capability × Agency
That’s a nice idea. Unfortunately, it’s also wrong.
A natural alternative might be to define delegation as Capability + Agency. But that breaks down quickly. You’d be implying that zero capability and lots of agency still leads to delegation. But you can’t hook up a potato to your server and expect it to help, no matter how much access you give it.
You might say, “Well, at least with a product, you avoid cases where one axis completely dominates the other.” And you’d be right. Capability × Agency is certainly better than Capability + Agency. At least with a product, zero still means zero. Multiplying a big number by zero still gives you nothing — which is closer to reality. But even that’s not quite right.
There are two problems with treating delegation as a simple product:
- It can’t go negative.
There’s no such thing as negative capability or negative agency — but there is such a thing as negative delegation. Sometimes adding an agent makes things worse. - The relationship is nonlinear and non-monotonic.
More isn’t always better. In fact, more can be much worse.
A baby with root access probably won’t do much, but it won’t do much damage either. A senior engineer offering advice but no keyboard time? Helpful, but not operating at full delegation capacity. An intern with a high opinion of themselves and production access? That’s when the pager goes off.
From the model side: connect Flan-T5 to your infrastructure and it’ll mostly flail. Low capability, high agency — nothing happens. Hook up a powerful model with some agency, and you start seeing real delegation. But give a sort-of-capable model too much agency, and now you’re in trouble. Case in point, it knows just enough to try chmod -R 777 / ...without knowing what that means.
That’s not delegation. That’s a liability. And that’s why we need a curve — not just a surface.
The Geometry of Delegation
We can’t measure delegation directly. But we can model its surface — and visualize how it bends, breaks, or flattens under pressure.
We’re optimizing for cognitive delegation, how much mental effort we can reliably offload to an agent. We’ve argued that this depends on two core factors: the model’s capability and the system’s agency. Yes, this is a simplification. But it’s a useful one — one that captures most of the practical variance.
Which brings us to geometry.
In this section, we’ll move from abstract reasoning to visual intuition and explore how delegation behaves across the space defined by capability and agency. Because the real danger isn’t just in low values — it’s in how the surface bends.
Interpolating Toward the Ideal Agent
Before we get into how the surface bends — that is, the shape of the function:
... let’s work backwards from the top. What does the ideal agent look like?
If cognitive delegation is what we want to maximize, the answer is simple: we want high agency and high capability. Not one or the other — both, simultaneously.
Let’s go back to the code agent analogy. The ideal setup isn’t just having a brilliant engineer advising from the sidelines. It’s having that engineer hands on keyboard, actively making changes, fully plugged into the system, and working in domains they understand deeply.
That’s the corner of the space we’re trying to reach — the one where delegation becomes effortless, safe, and scalable. Everything else on the surface is an approximation of that ideal.
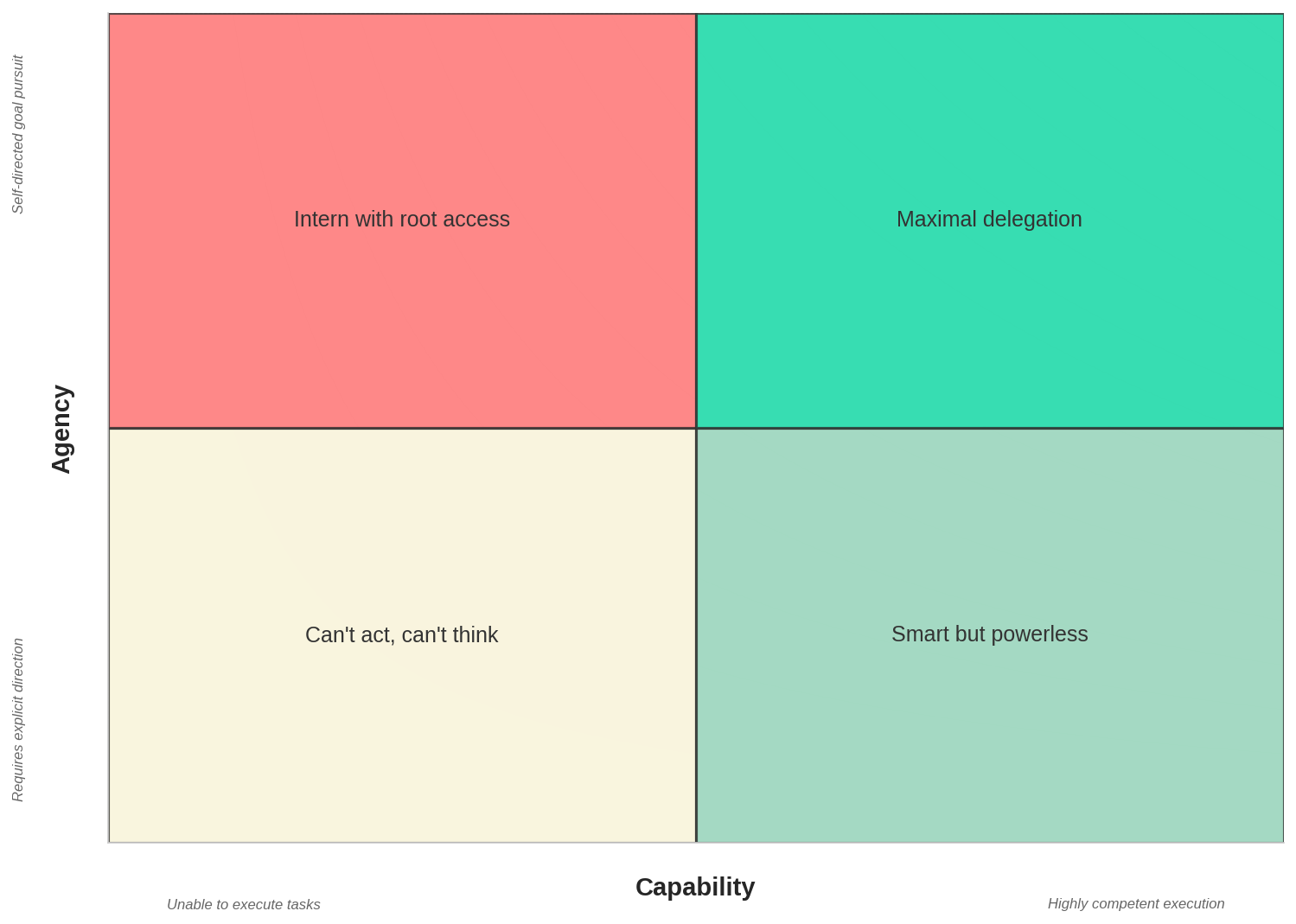
Where Things Go Wrong
Earlier, I made the case that cognitive delegation isn’t always positive — and more importantly, that it’s non-linear and non-monotonic. To put it simply: more isn’t always better.
To build intuition, let’s simplify the space and look at just two dimensions: cognitive delegation (Z) as a function of system agency (Y), assuming a high-capability model.
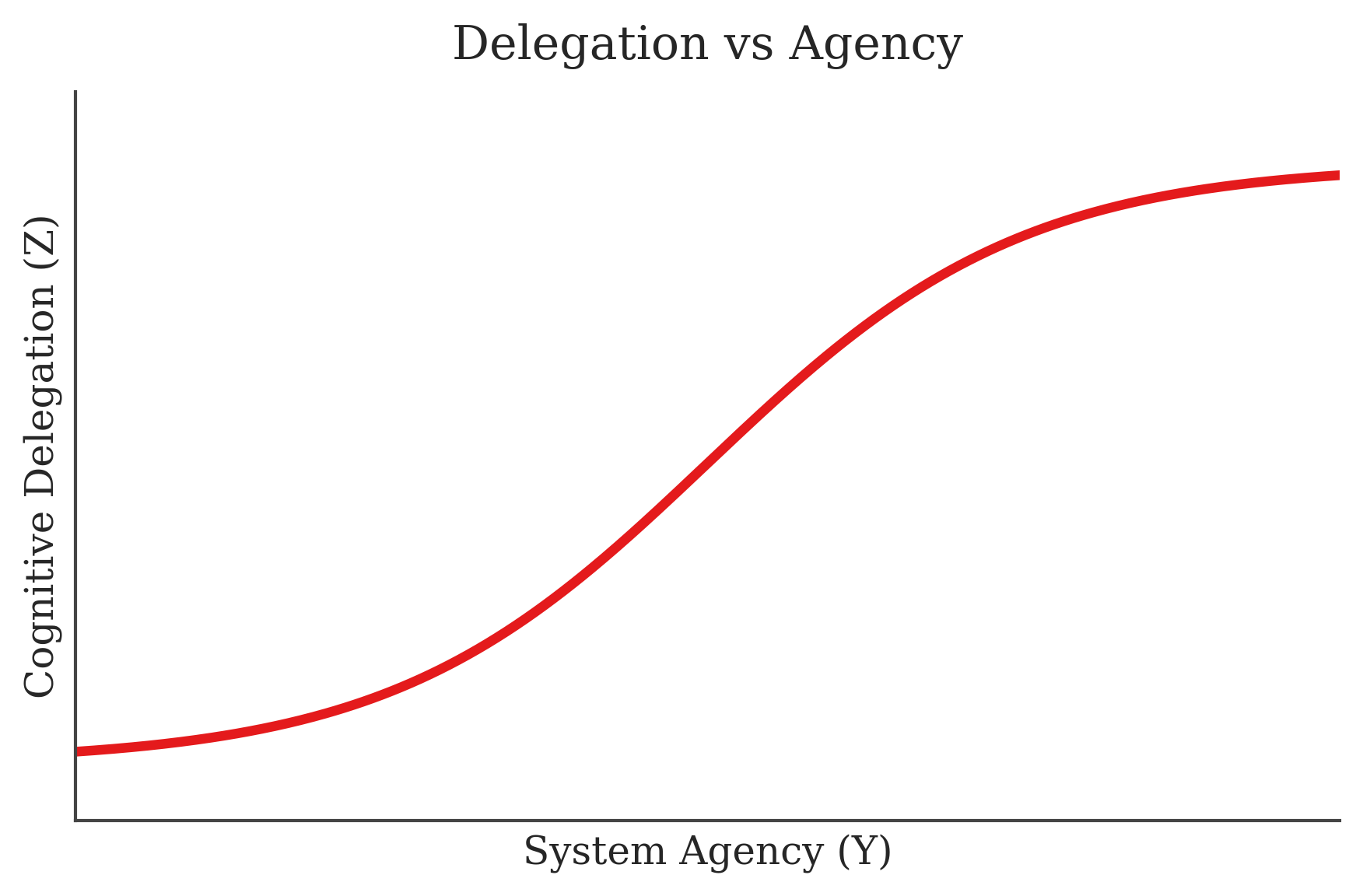
What does this curve look like?
It starts low — which makes sense. If the system has little agency, even a very capable model won’t help much. Think: brilliant engineer offering advice from the sidelines. Helpful, but limited.
As we increase agency, delegation ramps up quickly. The system starts doing more than thinking. The engineer moves from advisor to operator.
But then… something interesting happens. The curve begins to flatten.
You could argue for a hockey stick here, exponential gains with more access, but I’ve chosen to model it with a logistic curve instead. Why? Because in most real systems, there’s a point of diminishing returns. Once the agent can reach all the meaningful parts of the environment, giving it more access doesn’t really improve delegation.
Once the agent already controls your entire cloud stack, giving it access to your archived Jira tickets probably isn’t going to move the needle.
Now let’s introduce a second curve — same axes, different system. This time, we’re holding capability low and seeing how delegation changes as we increase agency.
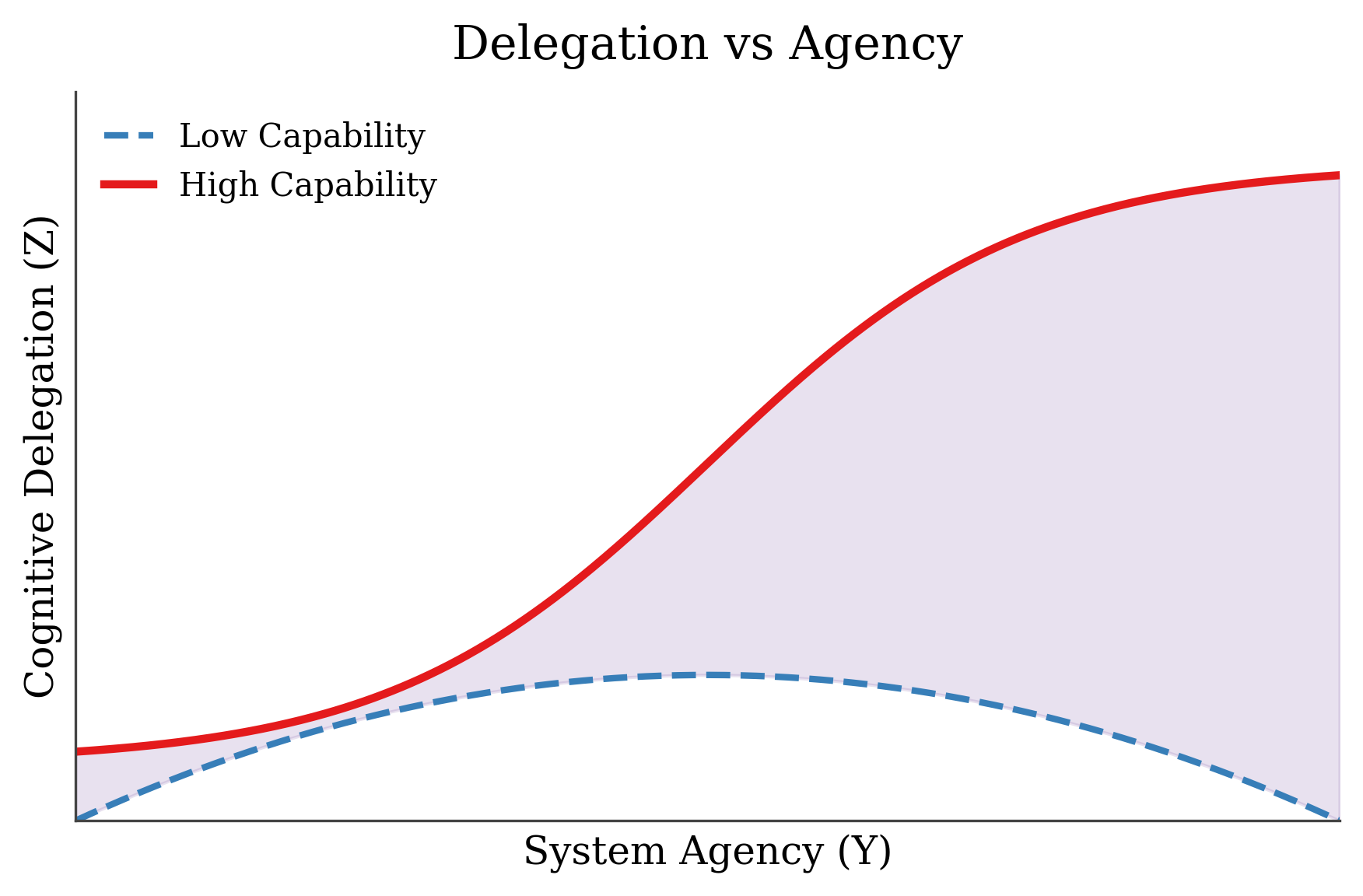
What emerges is something closer to an inverted parabola.
At low agency, delegation is low. No surprise there — a weak model that can’t act won’t do much. But as we give it more agency, delegation begins to rise. It’s still a weak model, but now it can do things, so it starts to appear useful.
And then it craters.
This is the failure mode I mentioned earlier: the intern with root access. The model is confident enough to act, but not competent enough to understand the consequences.
The shaded region between the two curves, between the high-capability agent and the low-capability one, is what I call the capability gap. It’s the price we pay when agency outpaces intelligence.
And it’s where regret lives.
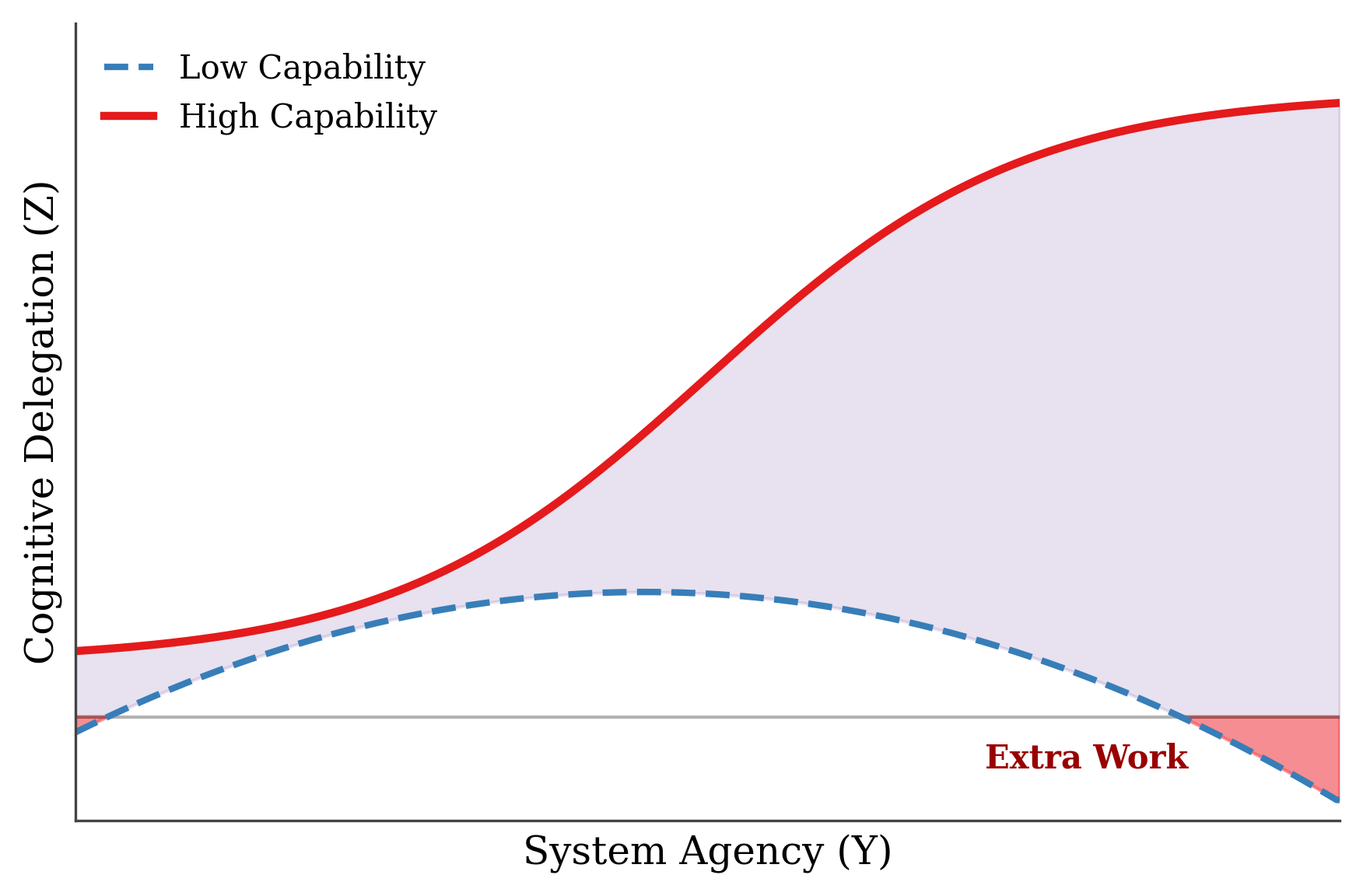
To make this more concrete: the low-capability curve doesn’t just plateau — it can dip below zero. In these regions, cognitive delegation becomes negative. The agent isn’t helping. It’s adding friction. It increases cognitive load rather than reducing it.
This is what happens when agency outpaces capability. The system demands supervision, recovery, or worse, debugging the work of the agent instead of solving the task.
And this isn’t just theoretical.
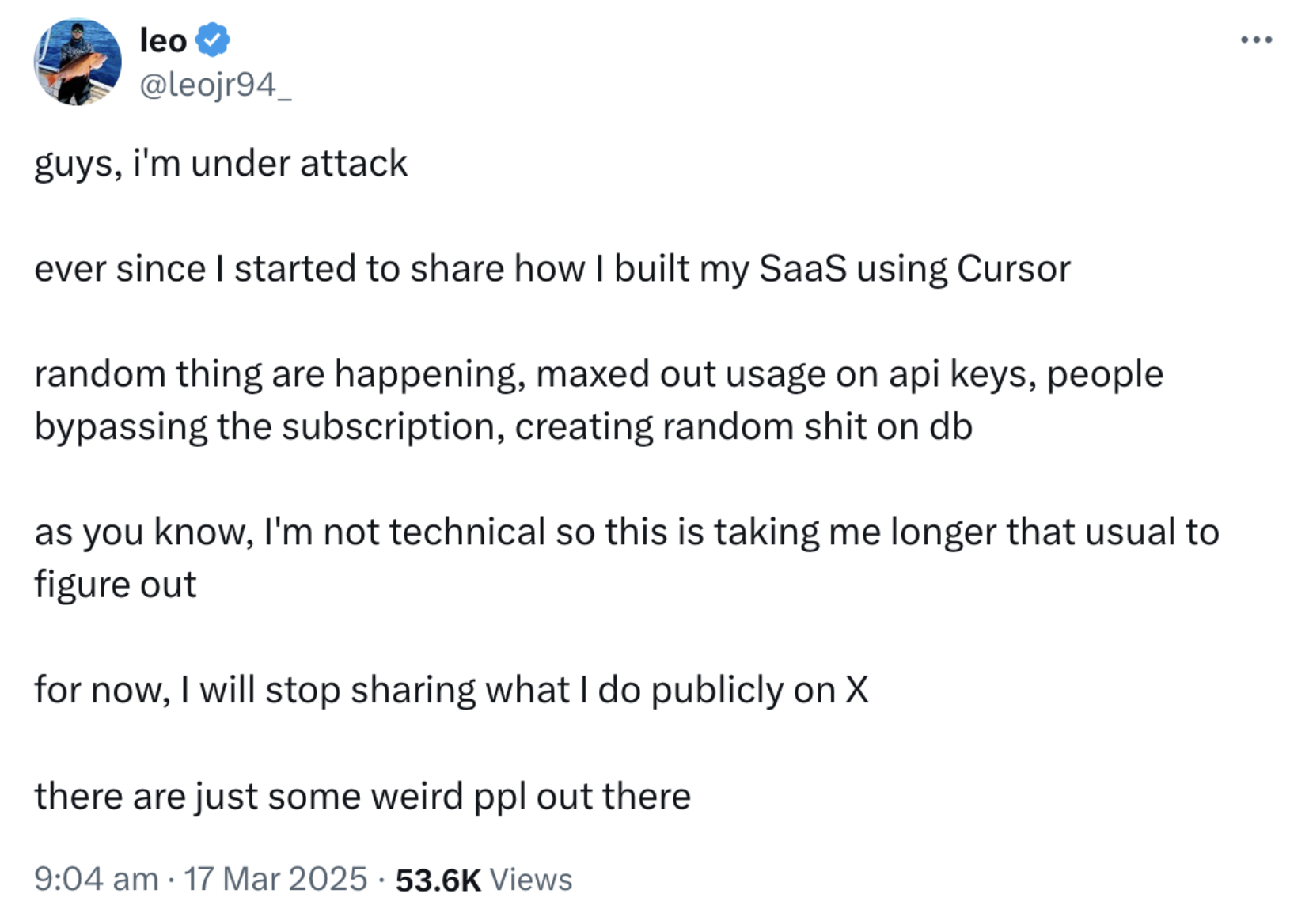
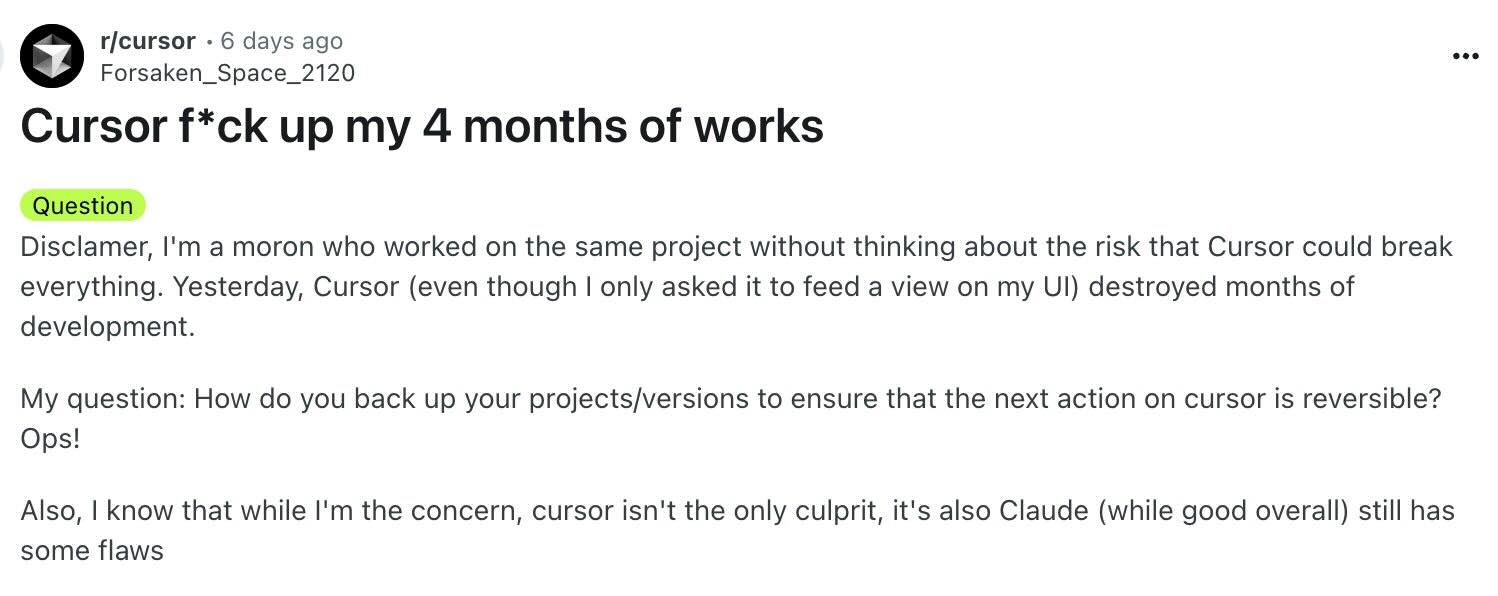
These are early signals of a deeper failure mode: systems that appear helpful, but quietly offload complexity back onto the human. They create more work than they save.
One objection you might raise is: “But Rohan, these users clearly didn’t know what they were doing. You can’t blame a low-capability model for that.”
And you’d be right — they didn’t. But that’s precisely the point.
Cognitive delegation doesn’t discriminate. Whether you’re an expert or a novice, the core question remains the same: Did the system reduce the cognitive work required to achieve the goal?
In that sense, even learning how to use the system is part of the delegation process. If it takes more thinking, more recovery, or more mental scaffolding to make the system useful, that cost counts.
If we’re going to build toward a world where agents enable high levels of delegation, that world needs to work for everyone. Not just power users. Not just engineers.
So yes, the users were inexperienced. But a well-aligned agent should compensate for that, not amplify it.
The Curve of Regret
Let’s define the delegation surface — not because the math is precise, but because it gives us something more valuable: structure.
This equation is not meant to be predictive. It will not give you a ground truth value for delegation, and it is not derived from first principles. Instead, it was constructed to match a shape I had in mind — to express how I intuitively think delegation behaves: how it rises, where it flattens, and where it can break down. The specific terms aren’t the point. The surface is.
The key idea here is the penalty term, which defines the steepness of what I call the curve of regret, the part of the space where agency outpaces capability and delegation begins to fail. When that happens, the surface bends downward.
The value of the penalty factor, α, controls how sharply that collapse happens. In high-stakes domains where failure is not an option, this penalty should be large. In benign use cases, like the interactive visualization below (which I built with help from Claude Code), the penalty matters less. The shape stays the same, but the curvature depends on the context.
The first term in the equation captures a saturating relationship: as capability and agency increase together, delegation improves — but only up to a point. The second term imposes a cost when that balance breaks. That’s where things start to go wrong. The shape of the surface is not universal. The steepness of the curve depends on the context: on how much failure matters, how tolerant the system is, and what’s at stake. It will vary from system to system, task to task, and user to user.
A Visual Language for Thinking About Agents
My goal in this piece hasn’t been to provide a formal theory of agents — because I don’t think that’s possible. There’s no equation that can perfectly regress the value of delegation, no universal metric for capability or agency. Instead, I’ve tried to offer something else: a way to see.
What I’ve presented here is an abstraction; one that simplifies, omits edge cases, and makes assumptions. With that being said, I still think it's useful and it’s how I reason about agents.
When I think about agents — their value, their limitations, their risks — I’m not running math in my head. I’m visualizing a surface. I’m imagining where a system might fall, how close it gets to the ideal, and where it might collapse into regret. I hope this surface gives you the same kind of intuition.
Below, you’ll find an interactive visualization that lets you explore this space. You can control three parameters:
- Capability – how intelligent the system is
- Agency – how much control it has over the environment
- Penalty – how steep the curve of regret becomes when capability falls short
The capability and agency sliders place a point on the surface. The penalty controls the shape of the surface itself, how much that point rises or falls based on the mismatch between control and competence. In other words, the same agent, with the same capability and agency, might sit at a very different height depending on how unforgiving the environment is.
Try moving the sliders. Plot your own systems. See how the delegation surface warps as the balance shifts. But most importantly, use this as a language, not a rulebook.
As agents become more complex, more autonomous, and more embedded in real-world workflows, we’ll need better ways to think about delegation — not just what we can build, but what we can trust. And for that, shape might matter more than precision.
A quick note
My good friend, Gabe Cemaj, pointed out something I left unaddressed in this piece:
“Where do humans sit on this curve? If we’re delegating cognitive load, what becomes our function? I can see why you might want to avoid that whole area of the argument, but I think it’s important.”
He’s right. I was avoiding it, partly because it drifts into the societal impacts of AI, rather than staying focused on agents themselves. But that doesn't make it any less essential. It probably deserves its own post, not a footnote tacked on at the end. Still, his question made it clear that I can’t ignore it entirely. So here’s a start of an answer.
It’s easy to reach for the familiar response: “Humans will adapt. We’ve automated things before. We’ll find new work.” Maybe. But I think that view is incomplete.
In past waves of automation, we offloaded narrow physical or symbolic tasks. We didn’t offload cognition itself. This time, we’re delegating what it means to process, reason, and act. That shift, in my opinion, is more fundamental. The implications are still unfolding.
Am I saying there’s no purpose for us? Not at all. I think this moment is less about removing ourselves and a bit more about redirecting attention. The more we can delegate reliably, the more we free up our thinking for ambiguity, novelty, and judgment; the parts of cognition that don’t flatten easily into a surface. In that sense, the goal isn’t to eliminate thought. It’s to reallocate it.
So where do we sit on the curve? I’d argue we don’t. At least not directly.
We sit above it. Orchestrating delegation, choosing when and where to trust, and calibrating how much to let go. And as systems gain more agency and capability, our role shifts again. We move into metacognition: deciding not just what to delegate, but how, why, and with what tolerance for regret. We get a meta-curve of regret of our own.
But that’s a deeper discussion. I’ll save it for another time.
Grateful to Gabe Cemaj, Sebastian Pilarski, Nikhil Gupta, Prateesh Sharma, and my dad, Nitin Pradhan, for the thoughtful conversations and sharp feedback that helped shape this piece.